之前介绍 Redis 持久化是针对单台主机,如果这台主机死掉,不能对外提供服务,那持久化策略也没有发挥的余地。
为了避免这种情况,那就需要能够有多台 Redis 服务器,哪怕其中一台死掉,再选择一个允许正常的 Redis 服务器顶上,继续正常服务。但我们必须要保证数据的一致性,所以引出接下来介绍的主从复制。
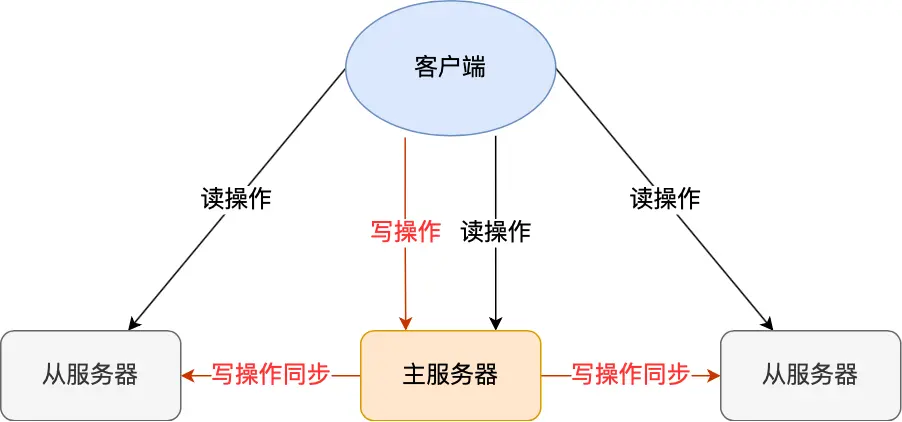
主服务器既可以读也可以写,从服务器只读。当主服务器写数据之后,要把最新的数据同步给从服务器,使得主从服务器数据一致。
第一次同步
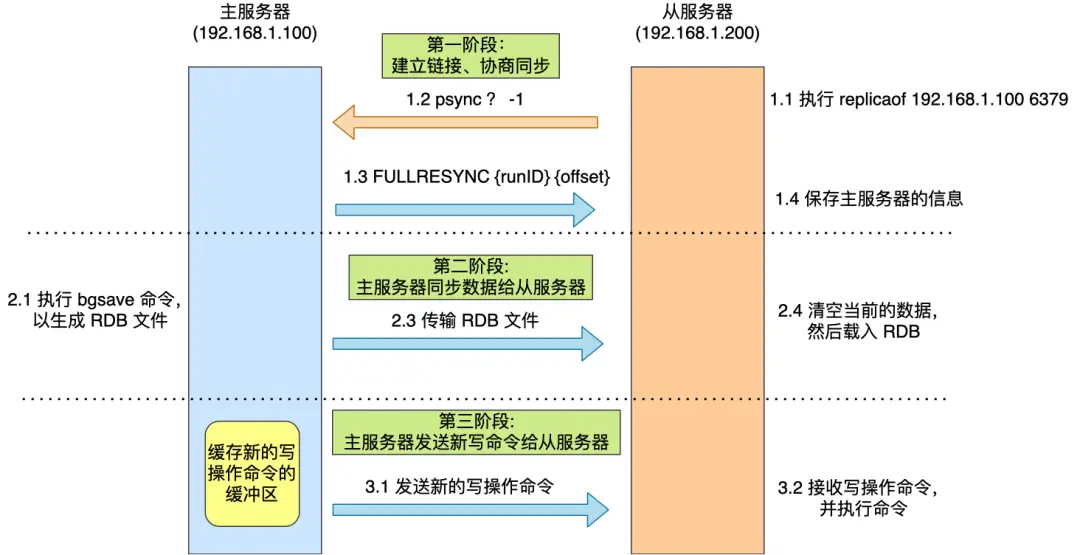
第一阶段:建立连接,协商同步
第二阶段:主服务器同步数据给从服务器,从服务器需清空已有的数据
第三阶段:主服务器发送新的写操作命令给从服务器
第一阶段:建立连接、协商同步
从服务器执行 replicaof 命令后,从服务器就会给主服务器发送 psync 命令,表示要进行数据同步。
主服务器收到 psync 命令之后,会用 FULLRESYNC 作为响应命令返回给对象。FULLRESYNC 响应命令的意图是采用 全量复制 的方式,也就是主服务器会把所有的数据都同步给从服务器。
所以,第一阶段的工作是为了全年复制做准备,至于具体这么做,看第二阶段。
第二阶段:主服务器同步数据给从服务器
主服务器会执行 bgsave 命令来生成 RDB 文件(不会阻塞主线程),然后把文件发送给从服务器。从服务器接收到 RDB 文件后,会先清空当前的数据,然后载入 RDB 文件。
后续主服务器的写命令会记录到 一个缓冲区中(replication buffer),来保证数据的同步。
第三阶段:主服务器发生新写操作命令给从服务器
从服务器完成 RDB 数据加载之后,给主服务器回复一个确认消息。主服务器接着把后续的写命令发给从服务器,即从 replication buffer 中所记录的写操作命令发送给从服务器,从服务器执行这些命令之后,这时主从服务器数据就保持一致了。
完成这一步,我们可以说主从服务器第一次同步完成。
命令传播
第一次同步之后,主服务器和从服务器会维护一个 TCP 长连接,后续主服务器有新的写命令就通过这个连接同步给从服务器。
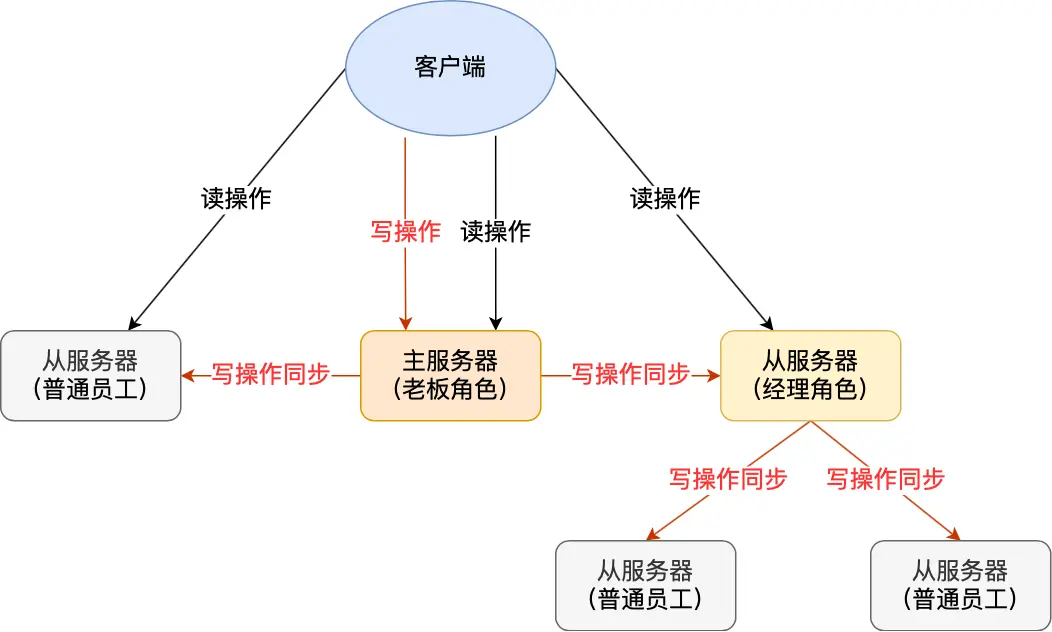
分摊主服务器的压力
第一次数据同步过程中,主服务器会做两件耗时的操作:生成 RDB 文件和传输 RDB 文件。
主服务器可以有多个从服务器,但是数量增多就会压力很大。我们可以让从服务器也作为主服务器,让新的从服务器来依赖它们,那么真正的主服务器的压力就会小很多了。
增量复制
之前讲第一次同步之后,主从服务器之间有一个 TCP 长连接。如果主从服务器间的网络连接断开了,那么就无法进行命令传播了,这时从服务器无法和主服务器保持数据同步了。
随后,连接恢复,该如何保证数据一致性呢?
主从服务器会采用增量复制的方式继续同步,也就是只会把网络断开期间主服务器收到的写操作命令,同步给从服务器。
⭐️内容取自《小林Coding》,仅从中取出个人以为需要纪录的内容。不追求内容的完整性,却也不会丢失所记内容的逻辑性。如果需要了解细致,建议访问官方网站。
