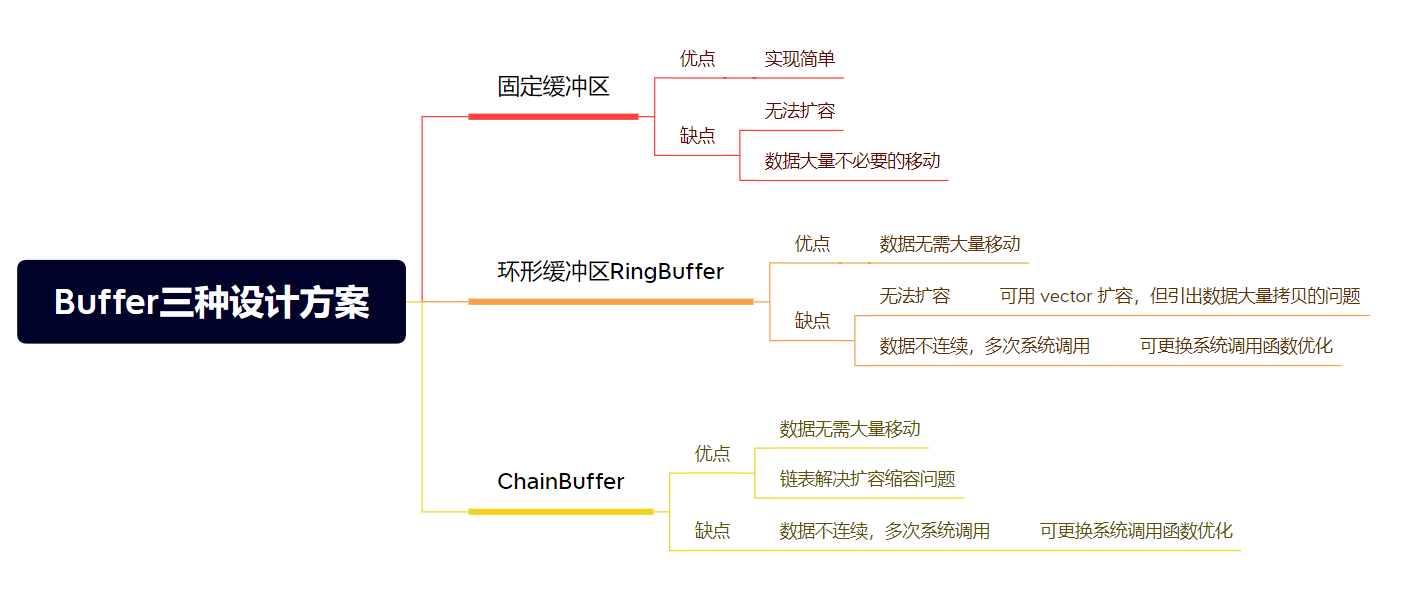
固定缓冲区大小
申请固定内存作为缓冲区,用一个写指针进行标识。
- 起始下标读取数据的起始地址,写指针是读取数据的结束地址。
- 如果写指针已经指向缓冲区末尾,将不允许写入。
- 读指针需要判断数据的完整性方可实际去读。通常我们采用 TLV 协议来解决网络传输中存在的粘包问题。
这种简单的方案在实际的生产中也是很常见的,如果你严格限制传输的数据大小,并且让自己的网络库足够的高性能,用户请求量不大的情况下,也是相当不错。Redis
的接收缓冲区,使用的是定长 buffer。
那么它的缺点是什么?尽管这些缺点我们也有优化方案。
- 需要频繁腾挪数据,只要界定成功一个完整数据包,就需要把后面的数据挪到前面,以空余更多的空间供生产者往里面填充数据。
- 需要实现扩缩容机制,如果缓冲区剩余空间不足以存放数据,需要对缓冲区进行扩容,并且将旧缓冲区中的数据挪到新缓冲区中。
第一个缺点的解决方案在下一个缓冲区设计中可以解决,如果各位用数组写过环形队列,你应该明白我们不需要每次在界定成功一个完整数据包,就把后面的数据挪到前面。
第二个缺点的解决方案在 C++ 中又有何难?vector 容器就是动态数组,但是我们通常不建议如此,因为扩容会导致数据的频繁移动,这实在是不可取。在最后一个缓冲区介绍中,我们可以利用 链表 设计出一个扩容但不必因为数据过大而频繁移动数据的缓冲区。
环形缓冲区 ringBuffer
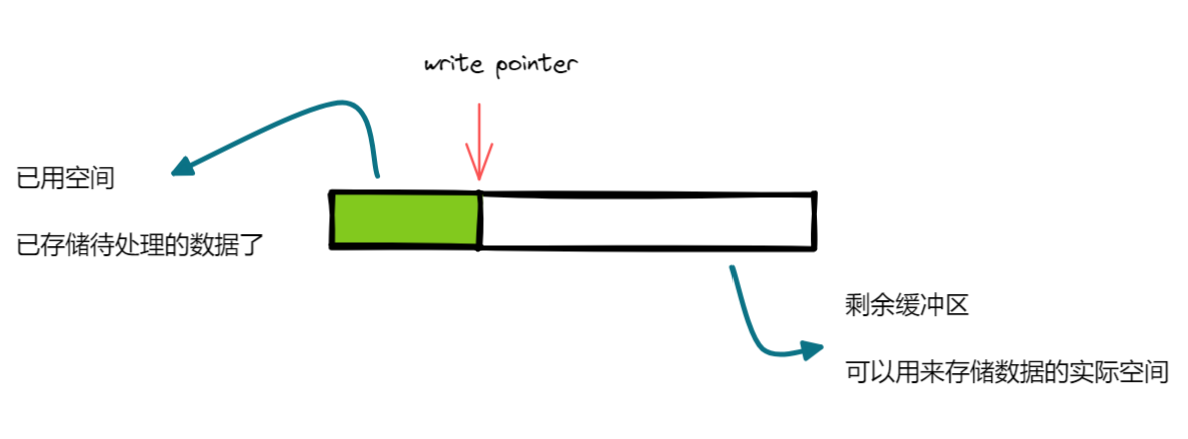
用数组形成的环形缓冲区只是一种抽象,本质上还是一块连续的内存空间。用读指针(read pointer)和写指针(write pointer)进行标识。
下面简单演示环形数组如何解决固定缓冲区的第一个不足:
红色块代表已处理的无效数据,绿色块代表待处理的有效数据。此前的固定缓冲区会选择先清理无效数据,再把有效数据往前挪动。但是既然已经是垃圾数据,又何必管它呢?我们只需要管理好有效数据即可。
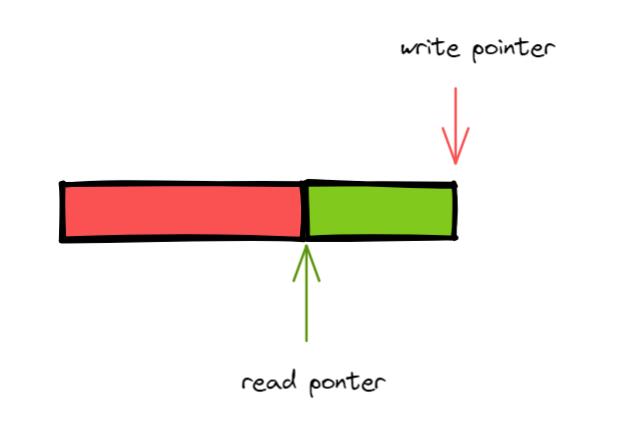
接下来又有新数据到来,这个时候的指针和数据存储是怎样?
它无需移动任何数据,只是通过写指针指向有效数据的末尾即可。Linux 网络数据的处理就用到固定大小的环形缓冲区,名字就叫 ringBuffer。
但我们明显也看到它由于固定缓冲区大小还是面临相同的问题,如果数据量过大,将会导致之前传输过来的数据被覆盖,这是相当糟糕的。之前的固定缓冲器是容纳不下后来的数据,可以选择丢弃,至少保证之前的连接的消息能够正确处理。而环形缓冲区会导致数据混乱,即得到的数据很有可能不是自己应该处理的数据。
可以考虑用 vector,只需要合理更新下标的范围,以及应该设置一个最大空间的阈值和恰当时刻的缩容机制。
还有这般设计又出现另一个值得考虑的问题,即数据不再像前面的固定缓冲区那样必然连续,因为我们现在的数据有可能前面有一部分,后面有一部分,基于操作系统的空间局部性原理,这个带来的性能损失也是应当考虑的。同样地,原先只需要调用一次 read,而这次将需要调用两次 read 才可以把数据完整的读取并存储下来,系统调用多一次。
可以更换系统调用函数来进行优化,即readv 和
writev 。用于处理向量
I/O,允许一次性读写多个非连续的内存区域。尤其在网络编程中,可以减少系统调用次数,提高性能,特别是在需要处理大量小数据块时。
1 | |
我们用核心代码简单看看两者之间的区别,这里就以 read 和 readv 来举例说明:
1 | |
只不过我们这里的 Buffer 指定一个就可以,但是起始下标和实际长度要指清楚,不要让数据被污染了。
优化 ringBuffer 之 chainBuffer
我们总是难以避免这个问题,即 vector 容器扩容导致的数据大量移动,可是我们又不得不避免固定缓冲区大小的局限。消息要尽可能多的存储起来(尽量不丢失用户的请求),需要避免固定缓冲区大小的局限,又不想承担扩容导致的数据大量移动。我们设计出下面这个缓冲区:
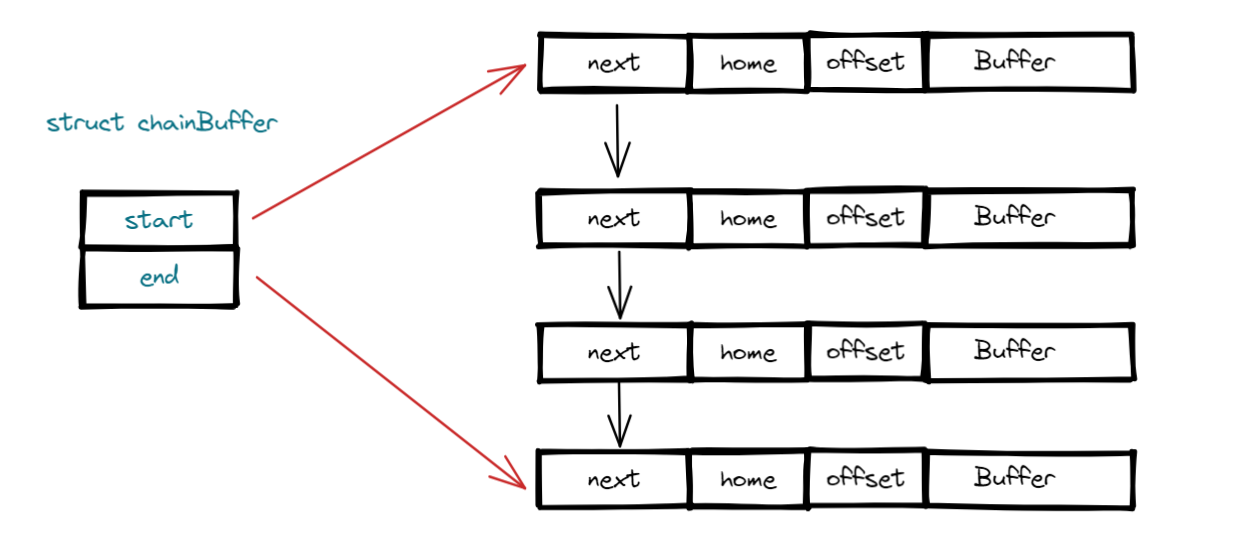
- start 指向缓冲区的头指针,end 指向缓冲区的尾指针。
- next 指向下一个缓冲区的节点,home 代表数据的起始地址,offert 代表数据的长度,Buffer 代表数据。
- 处理完数据更新头指针,添加新数据更新尾指针。
- 链表既解决扩容问题,也解决缩容问题(不需要就会被移除)。
我们的 Buffer 也是有大小限制的,如果不足以存储新来的数据就创建一个新的节点存储。在处理数据时,只有这个节点被合理的处理才可以移除,比方说当前节点的数据和下一个节点联合才是完整数据,务必处理为一个完整数据才进行移除。
链表的扩容方式的不足就是空间不连续,这在操作系统层面确实是一个不可忽视的缺点,如果你听说过空间局部性原理的话。再者也是和环形缓冲区一样,存在多次调用系统调用的情况。可采用之前提到的优化系统调用的方案。
总结