什么是文件描述符?
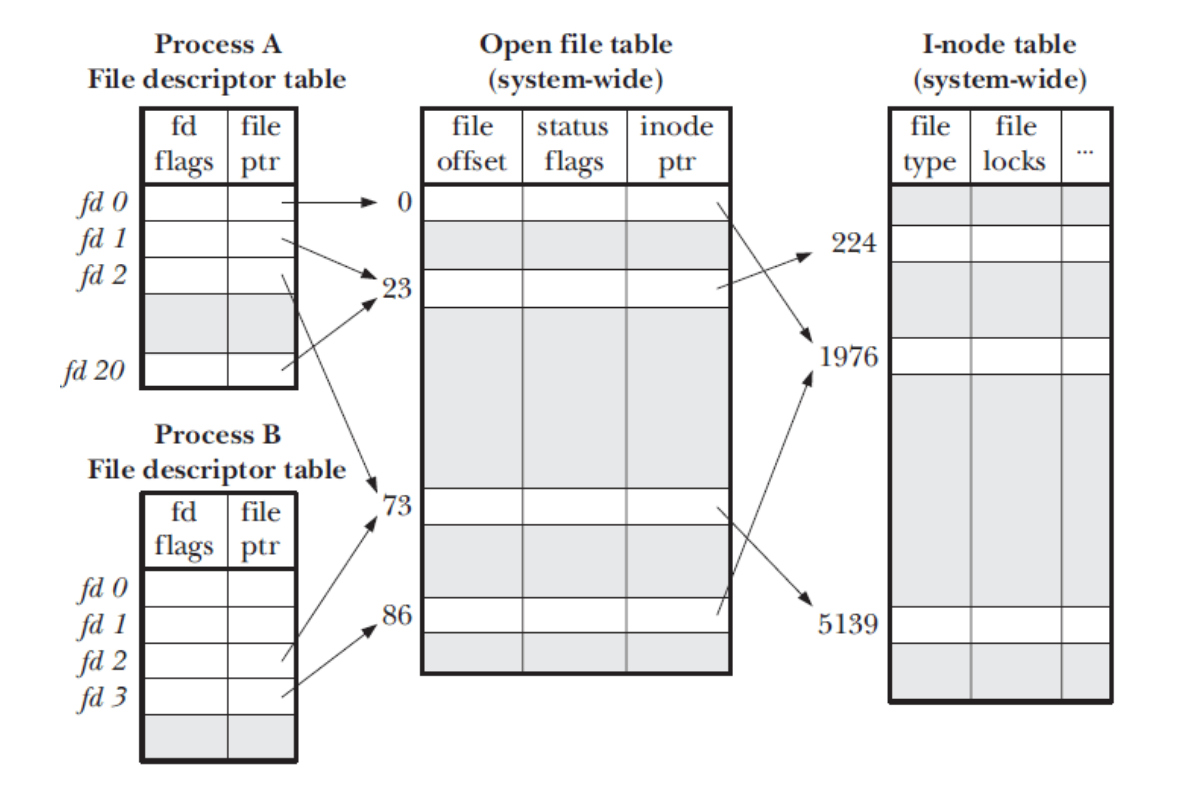
open 的返回值就是一个文件描述符,没有对文件进行任何操作,只是建立上面的三个数据结构。后续只需要拿文件描述符就等价于操作文件,从磁盘读入到内存的数据(这个动作不是 open做的)。
- 进程级 文件描述符表 ( file descriptor table )
- 系统级 打开文件表 ( open file table )
- 文件系统 i-node表 ( i-node table )
(一)文件描述符表
内核为每个进程维护一个 文件描述符表 ,该表每一条目都记录了单个文件描述符的相关信息,包括:
- 控制标志 ( flags ),目前内核仅定义了一个,即
close-on-exec - 打开文件描述体指针
(二)打开文件表
内核对所有打开的文件维护一个系统级别的 打开文件描述表 ,简称 打开文件表 。 表中条目称为 打开文件描述体,存储了与一个打开文件相关的全部信息,包括:
- 文件偏移量,调用 read() 和 write() 更新,调用 lseek() 直接修改
- 访问模式 ,由 open() 调用设置,例如:只读、只写或读写等
- i-node 对象指针
(三)i-node表
每个文件系统会为存储于其上的所有文件(包括目录)维护一个 i-node 表,单个 i-node 包含以下信息:
- 文件类型,可以是常规文件、目录、套接字或 FIFO
- 访问权限
- 文件锁列表
- 文件大小
- 等等
i-node 存储在磁盘设备上,内核在内存中维护了一个副本,这里的 i-node 表为后者。 副本除了原有信息,还包括: 引用计数 (从打开文件描述体)、所在 设备号 以及一些临时属性,例如文件锁。
对文件描述符的操作
open--打开文件描述符
1 | |
flags 是标志位,常见如下:
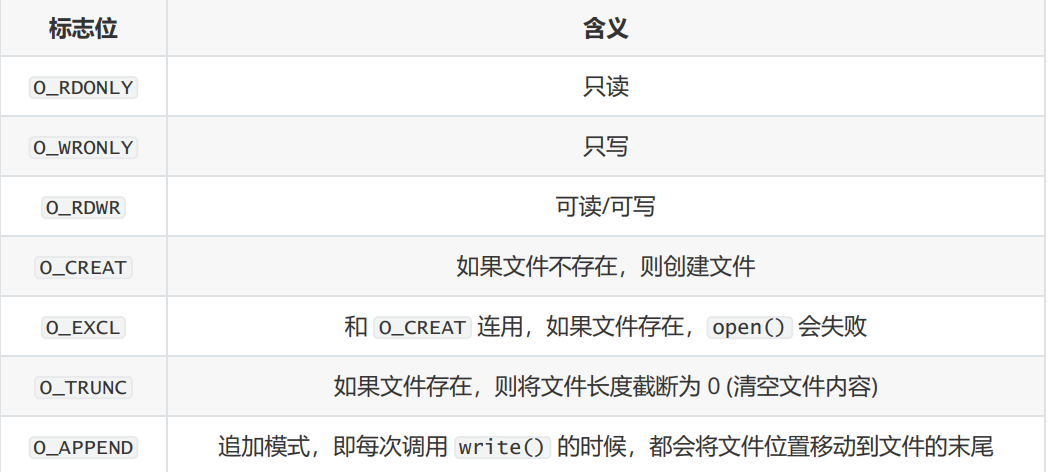
O_RDONLY、O_WRONLY、O_RDWR 中必须选择一个,且只能选择一个。
如果有 O_CREAT 标志位,必须填写第三个参数 mode。mode 用来指定文件的权限,会受 umask 的影响,实际权限为 (mode & ~umask)。
打开文件成功之后,得到文件描述符,后续利用该文件描述符就可以对文件进行操作了
close--关闭文件描述符
1 | |
read--读文件描述符
把文件描述符 fd 中的数据读取到 buf 中,预读取长度为 count。
1 | |
实际读取的数据长度为 read 调用成功的返回值。
write--写文件描述符
把文件描述符 fd 中的数据写入到 buf 中,预写入长度为 count。
1 | |
实际写入的数据长度为 write 调用成功的返回值。
lseek--移动文件位置
offset 代表移动的偏移量,就是你实际想要移动的长度
1 | |
whence 是参照点,有三个取值:

调用成功的返回值代表 移动后文件的位置。
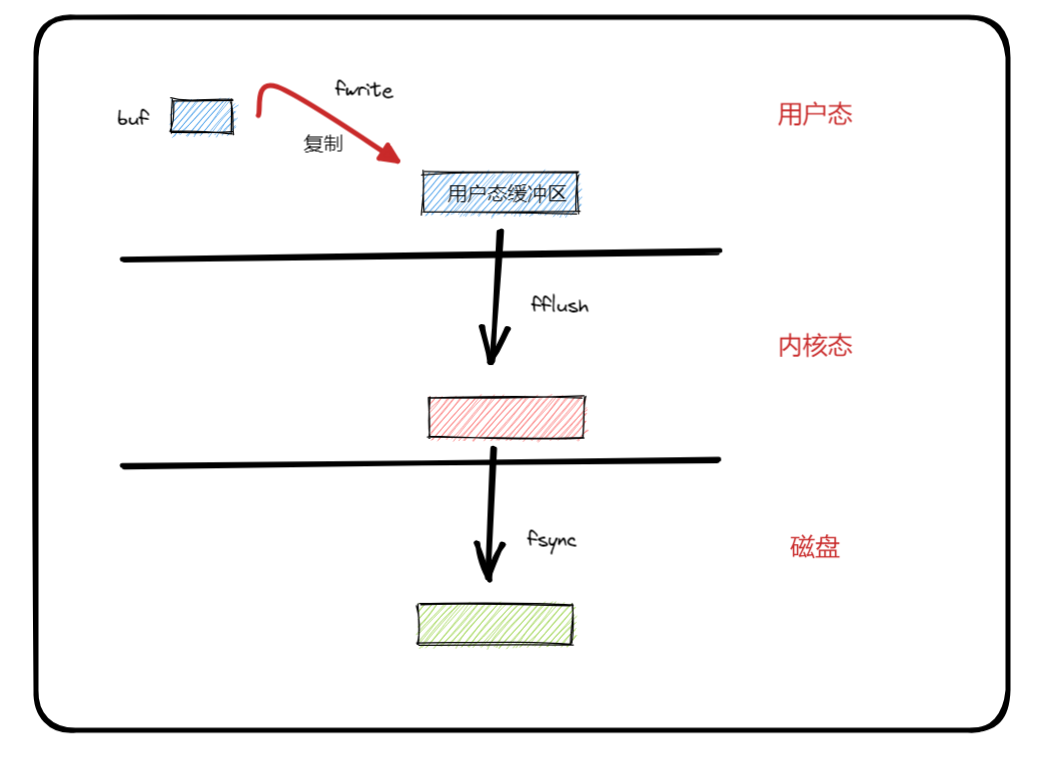
fsync--持久化到磁盘
前面调用 write 之后,并不会立即写入磁盘,写入的数据会由内核管理,由内核决定何时写入磁盘。
如果你想立即写入,调用 fsync 即可。
1 | |
这里要把 fsync 和 fflush 做个区分。fflush 是把用户态缓冲区数据 刷入到 内核缓冲区中,至于何时写入磁盘由内核决定。fsync 会把内核缓存区的数据立即写入磁盘。
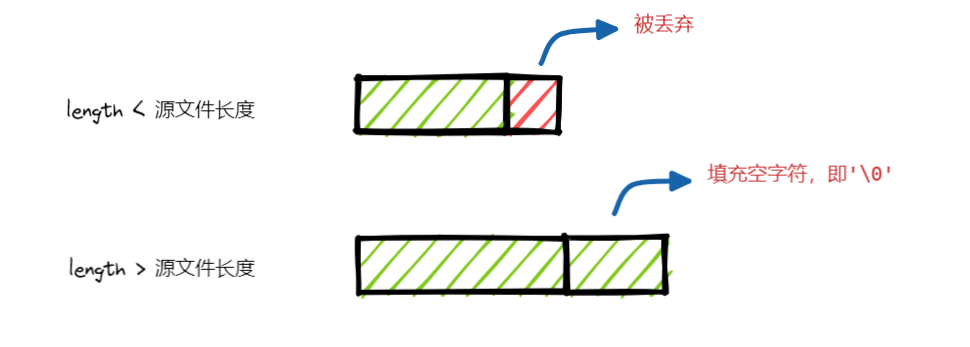
ftruncate--截断文件
1 | |
将文件截断为指定长度。分两种情况讨论:
- 如果 length < 源文件大小,那么超出部分的数据会丢失。
- 如果 length > 源文件大小,那么扩展的部分会填充空字符,甚至可能出现文件空洞。
fstat--获取文件的元数据
可以获取文件的元数据信息,这些信息来自于 i-node。我们也可以利用 stat 命令查看文件的元数据信息。
1 | |
先创建结构体 struct stat,调用 fstat 成功之后,元数据信息就会存储在 stat 结构体中。
1 | |
那么结构体 stat 存储哪些信息呢 ?
1 | |
dup2--复制文件描述符
不建议使用 dup,因为它不是原子操作,我们直接学 dup2 即可。
1 | |
从参数就能看出来,就是把 oldfd 复制给 newfd。
文件描述符和文件流
文件流是库函数,可移植性强;文件描述符是操作系统的系统调用,可移植性差。
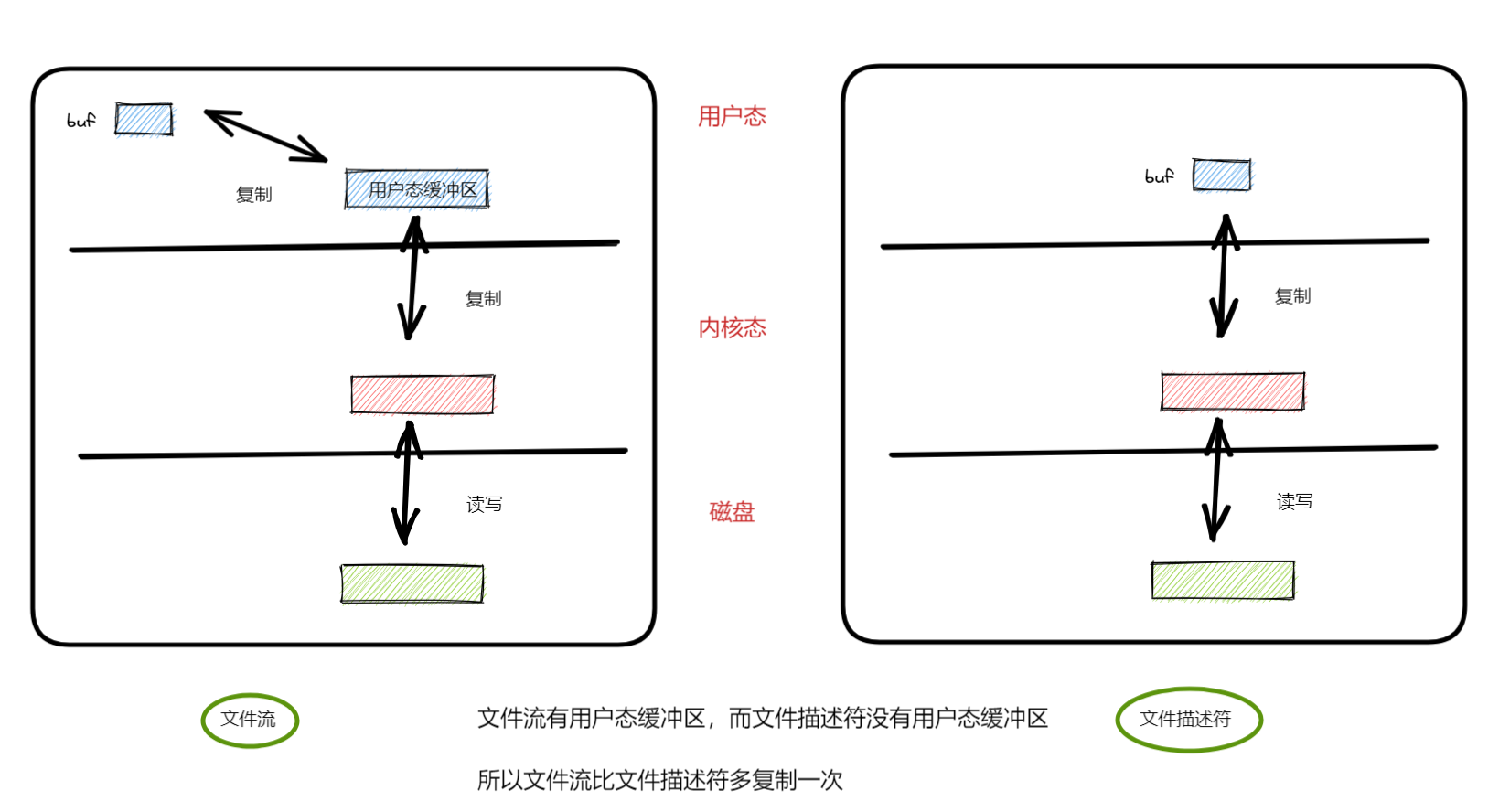
文件流有用户态缓冲区,而文件描述符没有用户态缓冲区,所以文件流比文件描述符多复制一次。那么它们各自的应用场景呢?
- 如果我们对文本操作,可以选择文件流进行操作,它更适合以人类的方式读写数据。
- 如果我们需要传输文件,可以选择文件描述符,它更适合以机器的方式读写数据。
特别是涉及大文件操作,必然要用文件描述符,毕竟要少拷贝一次。如果文件小用文本操作就方便,因为代码写起来比文件描述符容易。
内存映射I/O
内存映射可以将文件内容直接映射到进程的虚拟地址空间。当警察访问映射区域时,操作系统会负责将相应的文件部分加载到内存中。这种机制利用了操作系统的页面管理技术,可以高效管理内存和文件I/O。
内存映射的主要区别在于这两种类型:
- MAP_PRIVATE:创建一个私有的映射,任何对映射区域的修改不会影响到原始文件,也不会被其他进程看到。
- MAP_SHARED:创建一个共享的映射,任何对映射区域的修改会直接反映到原始文件,并且其他进程可以看到这些修改。
MAP_SHARED 状态下,两个进程共享同一块物理内存,即两个进程各自的虚拟内存映射到相同的物理内存。这两个进程在读写操作的情况下,都是直接作用于这块物理内存的(通过虚拟内存访问)。
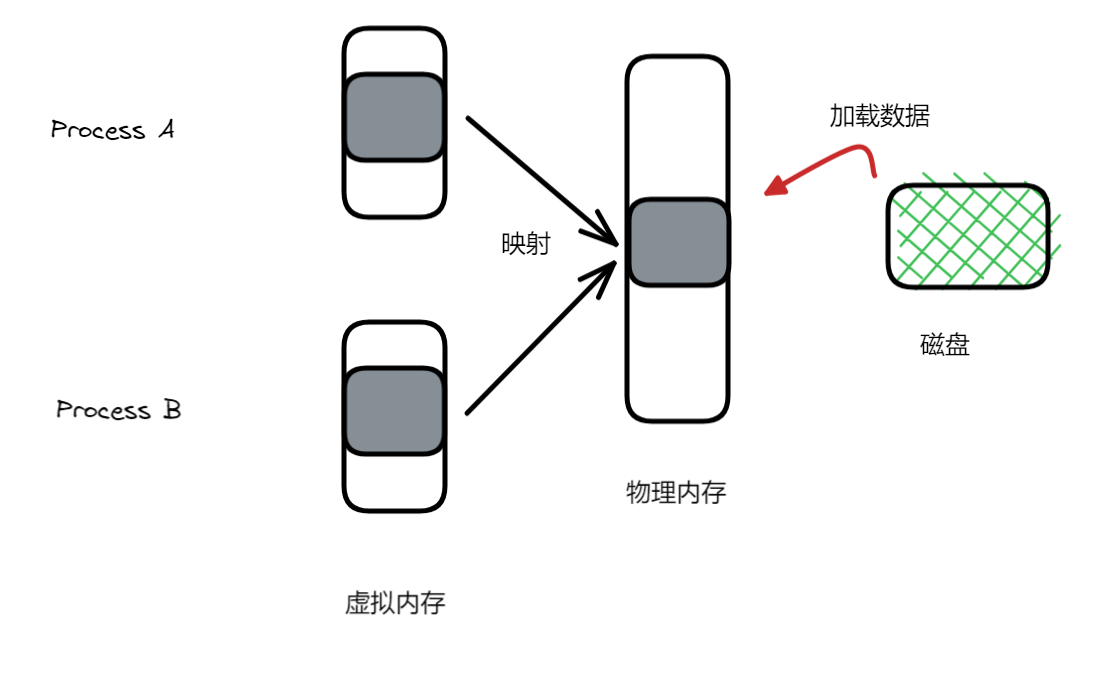
MAP_PRIVATE 状态下,依旧是和上面的情景一致,但如果有任意一个进程发生写操作,操作系统就会为这个经常重新分配一块内存(拷贝原来的内容,再让其修改),让其不对之前共享的内存进行操作,从此这个进程拥有这块属于自己的独立的物理内存,不与任何进程共享。
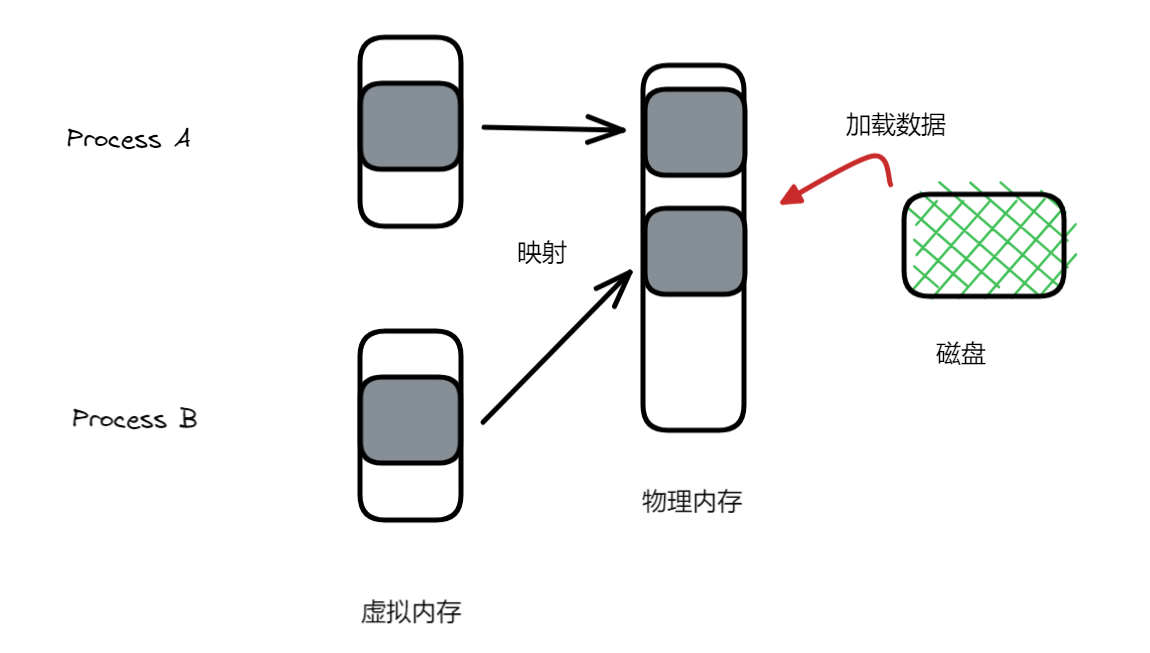
你可能会问,那么当进程 B 对其修改,操作系统会为其重新分配一块内存吗?不会,因为这块之前的共享内存知道只有一个进程指向它了,也就直接让它操作了。
mmap--创建内存映射
mmap
函数的返回值是一个指向映射区域的指针,如果映射成功,则返回指向映射区域的起始地址。如果映射失败,则返回
MAP_FAILED。
1 | |
addr:建议的映射起始地址(通常为
NULL,这样内核会为我们自动找到合适的地址)。
length:映射区域的大小,以字节为单位。
prot:映射区的访问权限。

flags:映射的类型和选项,如 MAP_PRIVATE
或 MAP_SHARED。
fd:要映射的文件描述符。
offset:文件中开始映射的偏移量,它必须是页大小的整数倍。
munmap--解除内存映射
1 | |
对于共享映射,数据在解除映射时会被写入文件(磁盘);对于私有映射,数据则不会被保存,即不会持久化到文件中(磁盘)。
实战:两个文件的零拷贝
文件从磁盘拷贝到内核缓冲区,是DMA操作:当从磁盘读取数据时,磁盘控制器通常会使用直接内存访问(DMA)技术,将数据从磁盘直接传输到内核缓冲区中,而无需 CPU 介入。这样做的好处是可以释放 CPU 去处理其他任务,提高系统的整体效率。
从内核缓冲区拷贝到用户缓冲区,是CPU操作:
从内核缓冲区将数据传输到用户空间缓冲区时,需要 CPU
介入。这个过程通常涉及系统调用(比如
read()),在内核态和用户态之间进行数据拷贝。这一步之所以需要
CPU
是因为内核需要进行内存访问权限的检查,并确保内核空间数据的安全性。
代码地址:系统调用 read 和 write 实现文件的复制
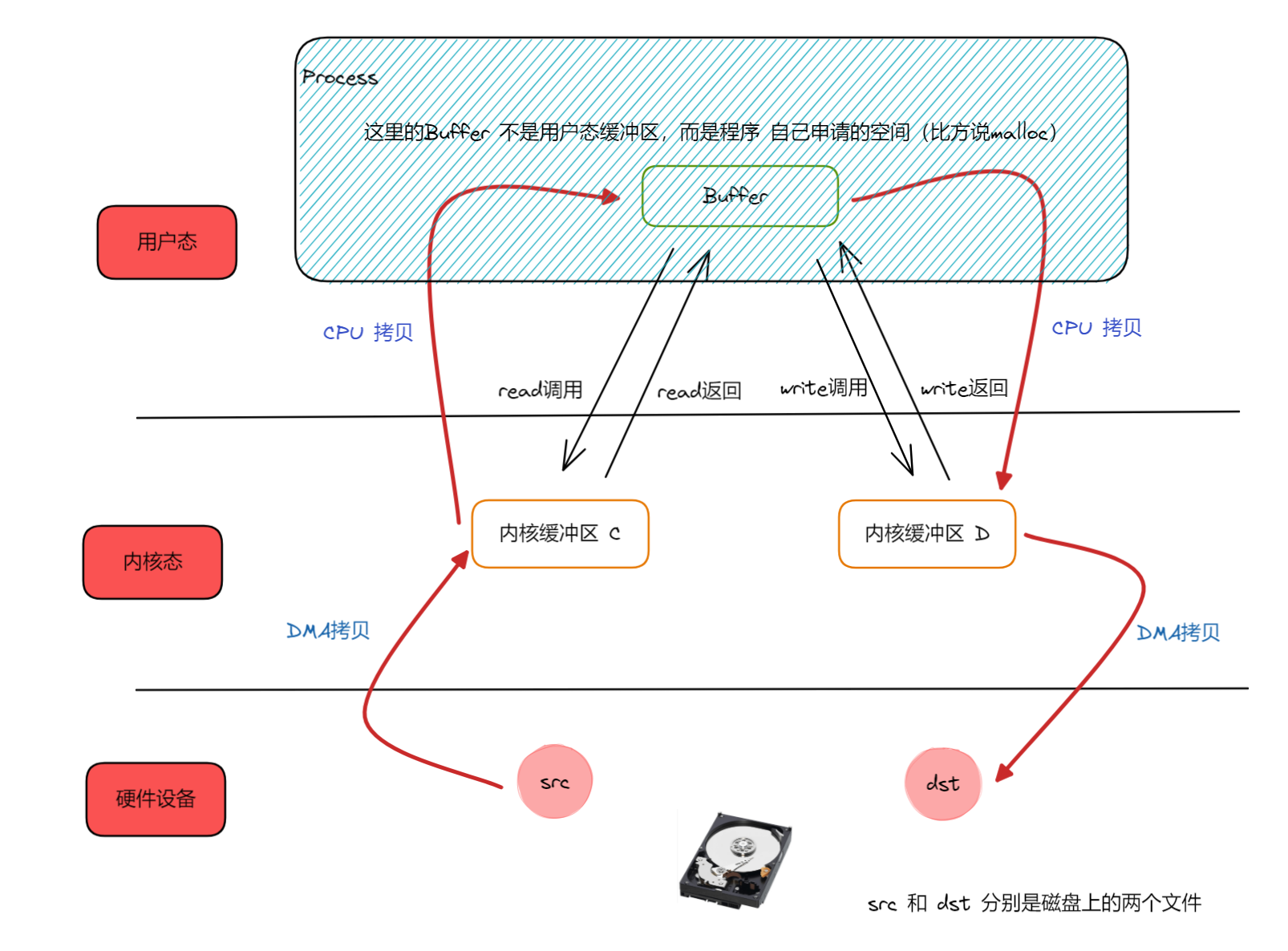
传统的 IO 读写方式,如上图中把 src 文件 读取并写入到 dst 文件中,整个过程就包括了四次用户态/内核态的上下文切换,四次数据的拷贝(DMA拷贝是读写,CPU拷贝是复制)。
代码地址:使用 mmap 实现文件的复制
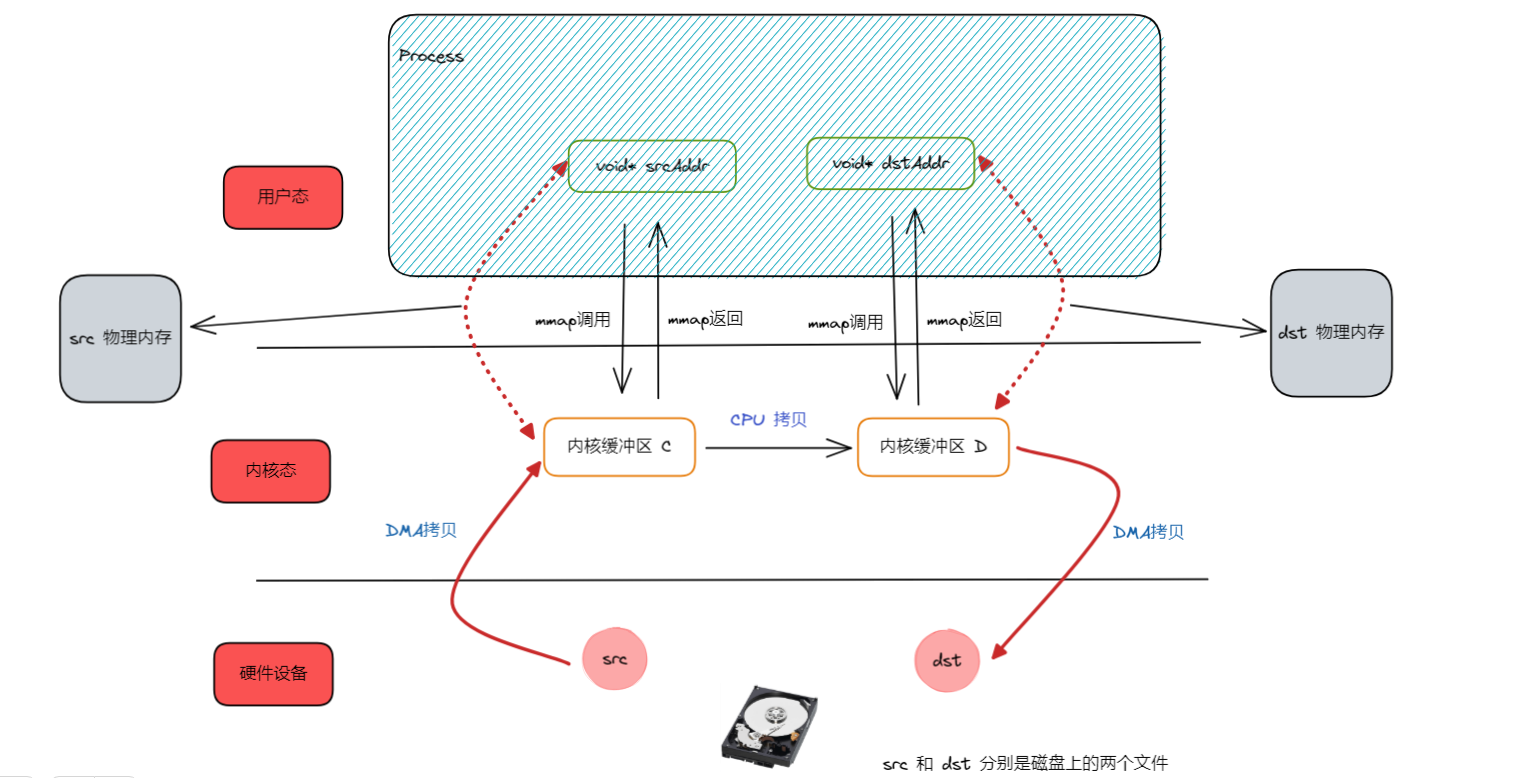
mmap 将用户空间的虚拟地址和内核空间的虚拟地址映射成同一个物理地址。调用 mmap 的时候,也就是开始把磁盘中的数据 DMA 拷贝到内核缓冲区,通过内核态的虚拟内存地址可以访问到这块物理内存。然后 mmap 成功之后,就是把 用户态的虚拟地址(你问它从何而来?第一个参数为NULL,操作系统会自动帮我们找好,最后映射物理内存的首地址作为返回值)和 内核态的虚拟内存地址 映射到同一个物理地址,这样通过用户态的虚拟地址访问物理内存,就等价于原先通过内核态的虚拟地址访问物理内存。
至此,我们不需要把内核缓冲区的数据拷贝到用户态的 Buffer 中。因为用户态的虚拟内存地址和内核态的虚拟内存地址是指向同一块物理内存的,那通过 memcpy 操作用户态的两个虚拟内存地址,就是将实际指向的物理内存 src 拷贝到 物理内存 dst。以此实现文件拷贝。
我们创建的映射是有大小的,所以是先映射文件的一部分(mmap 第三个参数 length),完成拷贝之后,接着继续映射下一部分。图中没有体现,而是直接映射整个完整的文件了,实际并非如此。
参考链接见下:
