什么是函数式编程?
我们常用的是命令式编程,它关心“怎么做”,而函数式编程关心“做什么”。通俗来讲,函数式编程更关注结果的定义,而命令式编程更关注实现的步骤。
命令式编程
在命令式编程中,我们会明确地告诉计算机每一个步骤应该怎么做。在如下这个代码中,我们使用了一个循环,逐个元素地累加到
sum 变量上。我们需要明确地描述每一步操作。
1 | |
函数式编程
在声明式编程中,我们更关注的是“做什么”,而不是“怎么做”。使用函数式编程的风格,我们可以使用递归或者标准库的算法来实现这一点。在如下这个代码中,std::accumulate
函数定义了如何计算数列的和,而不需要手动地进行循环和累加。这里编程语言提供的库函数实现了所有细节,程序员只需要指定“想要什么”,而不需要关心“如何去做”。
1 | |
纯函数
函数式编程的核心思想是纯函数,即函数只使用(而不修改)传递给它们的实际参数计算结果。如果使用相同的实参多次调用纯函数,将得到相同的结果,并不会留下调用痕迹(无副作用)。这都意味着纯函数不能修改程序的状态。
但是这样的要求未必过于苛刻,意味着纯函数不能从标准输入读取内容,不能向标准输出写入内容,不能创建或删除文件,也不能像数据库插入记录等。如果要追求彻底的“不变性”,甚至要禁止纯函数改变处理器的寄存器、内存或其它硬件的状态。这样的纯函数的定义就没意义了。
CPU 一条一条地执行指令,他需要跟踪下一条要执行的指令。如果连 CPU 的内部状态都不可修改,那么在计算机上将无法执行任何操作。另外,如果不能与用户或其它软件系统交互,程序就毫无作用。
正是因为如此,我们降低一下纯函数的要求,重新定义如下:任何没有可见副作用的函数称为纯函数。纯函数的调用者除了接受它的返回结果外,看不到任何它执行的痕迹。本书不提倡只使用纯函数,而只是限制非纯函数的数量。
下面通过命令式实现的统计文件集合中每个文件的行数的例子额,引入函数式编程的风格。
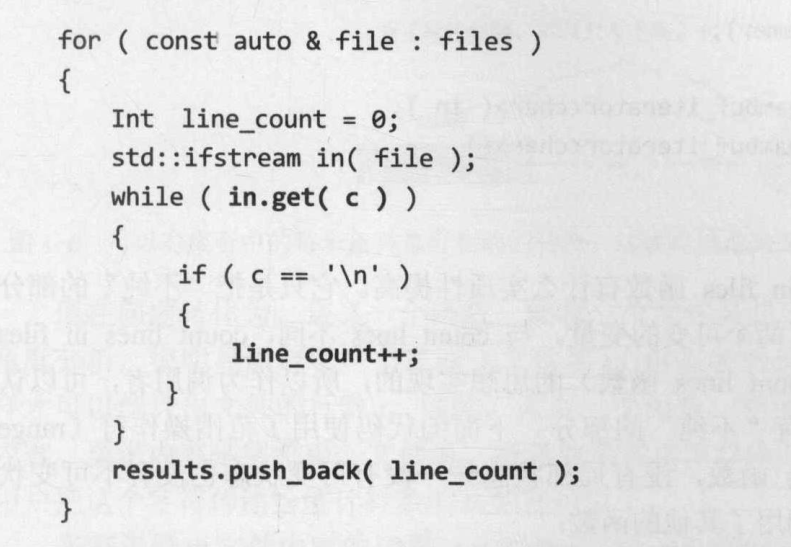
上面的这份代码 count_lines_in_files 就是常见的命令式编程方式,里面包含多个可变状态,相当“不纯”。
- get 方法每次都会更改字符的值
- 如果遇到换行,line_count 会自加更改值
- 退出 while 循环之后,results 容器会加入新的元素
但要考虑的不仅仅是这些,另一个很重要的方面是这个函数的“不纯”性是不是外部可见的。这个函数的所有可变变量都是局部的--计时函数的并发调用也不会共享--不会被调用者或其它实体看到。虽然它的实现不是纯函数,但它的使用者可以认为这是一个“纯函数”。这对它的调用者是有利的,因为不需要修改它们的状态,而只需要管理自己的(状态)。这样做的话,必须保证不能更改不属于自己的任何东西。如果限制修改属于自己的状态,以纯函数的方式实现,那就再好不过了。如果能够保证以纯函数实现,那就没必要考虑是否漏掉了任何状态改变,因为没有修改任何东西。
第二种解决方案把统计功能分离到另一个函数 count_lines 函数中,这个函数也是外表上看起来像个纯函数,虽然它的内部声明了一个输入流并且修改它。

实际上这份代码并没有对之前的程序 count_lines_in_files 没有什么实质性的提高。它只是把“不纯”的部分转移到其它地方,但依旧保留了两个可变的变量。与此不同的是,count_lines_in_files 不需要 I/O,但还是用它(count_lines 函数)的思想实现的,所以作为调用者,可以认为它是纯函数,而不论是不是含有“不纯”的部分。
下面的代码使用了范围操作符实现 count_lines_in_files 函数,没有局部状态--没有可变状态也没有不可变状态。它的实现只是对给定的输入调用了其它的函数:

这个解决方案就是函数式编程很好的例子。它简明扼要,浅显易懂。更重要的是,其他的事情(除统计行数外)它一概没做--没有任何可见的副作用。它只是对给定的输入给出期望的结果。
以函数方式思考问题
先写出命令式编程的代码,再去转换为函数式编程的代码是低效的,应该在拿到任务之前思考输入是什么,输出是什么,输入到输出需要怎样的转换,而不是去思考算法的步骤(命令式编程)。
给定一个文件名字的列表(集合),需要计算出每一个文件中的行数。首先想到的应该是简化这个问题,即一次只处理一个文件。虽然给定了一个文件名的集合,但可以一次一个地处理它们。如果能找出解决统计一个文件行数的办法,就可以很容易地解决这个问题。
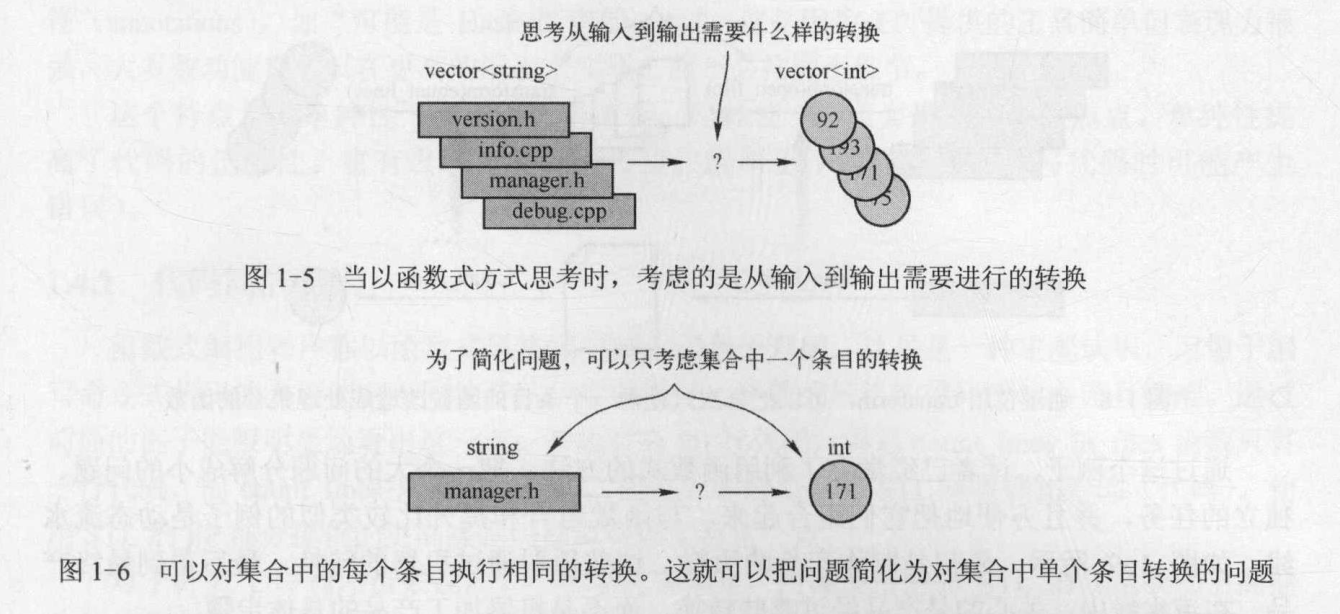
现在问题转化为,定义一个函数,接收一个文件名并计算该文件中行数的问题。从这个角度分析,很明显给定了一个东西(文件名),但需要的却是另一个东西(文件的内容,这样才可以统计出文件的行数)。因此,需要一个函数,它可以接收一个文件名,并给出它的内容。至于内容是字符串、文件流、或其他形式由用户决定。它只需要每次提供一个字符,用户把这个字符传递给统计行数的函数就可以了。
当有了给出文件内容的函数(std::string → std::ifstream),就可以用它的结果调用统计行数的函数(std::ifstream -> int)。把第一个函数返回的 ifstream 类型的结果传递给第二个统计行数的函数,就可以得到想要的结果。
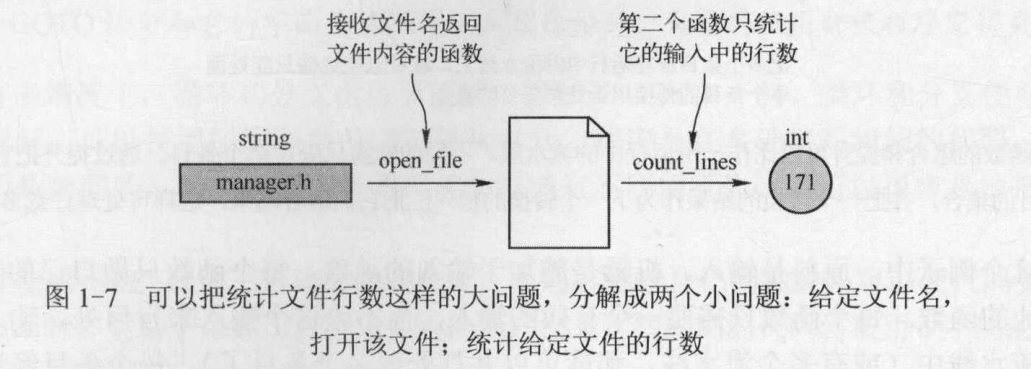
这样问题就解决了。现在需要提升这两个函数用于处理一个文件的集合,而不再是单一的一个文件了。从概念上讲,std::transform 就是这样实现的(还有很多复杂的 API):它需要一个可以应用于单个值的函数,并创建一个可以处理整个值集合的转换,如下图所示。把处理单个值的函数提升为处理该类型复杂数据结构的函数,是一种通用技术。
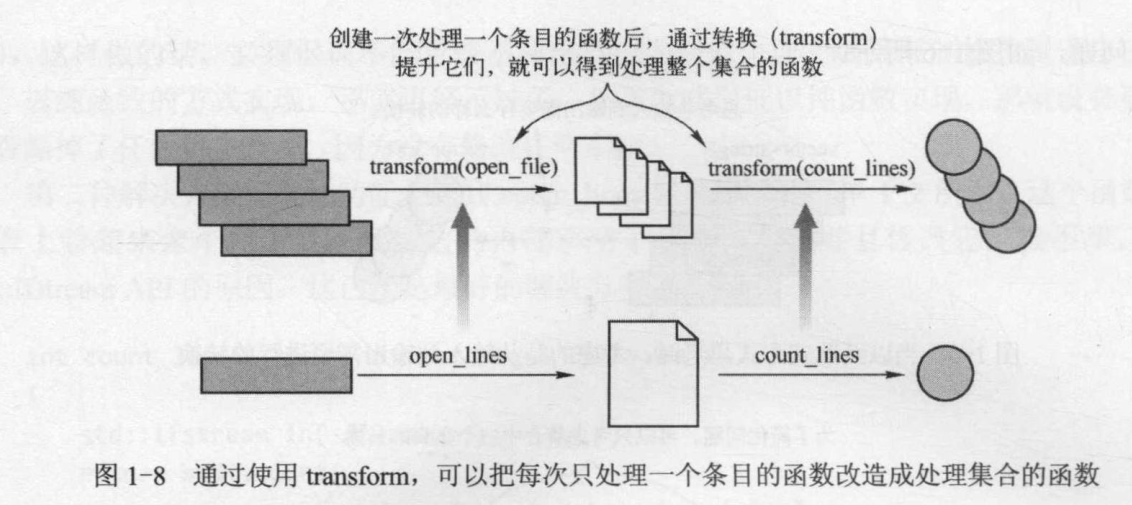
通过这个例子,读者已经学会了利用函数式的方法,把一个大的问题分解成小的问题、独立的任务,并且方便地把它们组合起来。与函数组合和提升比较类似的例子是动态流水线,如下图所示。最初是制作产品的原料。这些原料通过机器的转换,最后得到最终产品。在流水线中,关心的是产品经过哪些转换,而不是机器加工产品的具体步骤。
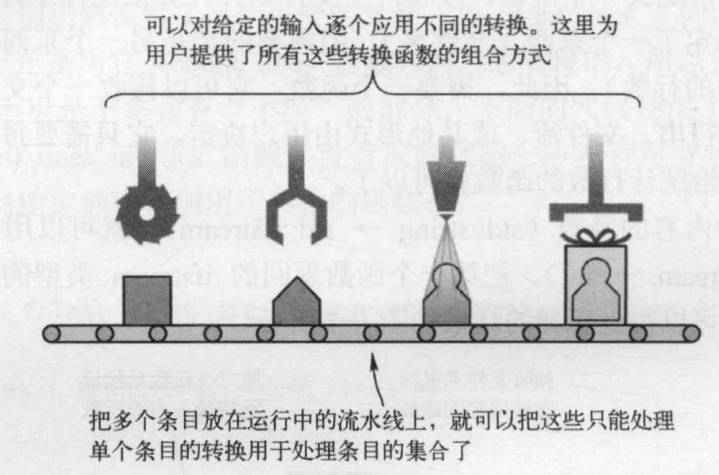
在这个例子中,原料是输入,机器是施加于输入的函数。每个函数只做自己的工作而不关心其他的函数。每个函数只需要一个有效的输入,而不论这个输入来自何处。输入条目逐个放在流水线中(或有多个流水线,那就可以并行处理多个条目了)。每个条目经过转换,最终得到想要的东西。
函数式编程的优点
代码简洁易读
有许多情况下,循环和分支也过于原始。就好像 GOTO 一样,循环和分支使程序难以编写和理解,可以使用层次更高的函数式编程结构替代。程序员在多处编写相同的代码,却没有发现它们是相同的,因为它们用于不同的类型或有不同的行为,但可以很容易地把它们重构出来。
通过使用STL或第三方库提供的抽象,并通过创建自己的抽象,可以使代码更安全更简短。同时,更易于暴露这些抽象中的缺陷,因为这些相同的代码将被用于不同的场合。
并发和同步
开发并发系统的主要难点在于共享可变的状态。必须保证组件不能相互干扰。使用纯函数编写并行程序就很简单,因为这些函数并不修改任何东西。不需要原子或信号量进行显式同步,可以把用于单线程的代码,几乎不加修改地用于多线程系统。
持续优化
使用抽象层次更高的 STL 或其他可信的库函数还有另一个优点:即使不修改任何一行代码,程序也在不断地提高。编程语言、编译器实现或正在使用的库的实现的每一个改进都将改进程序。虽然函数式或非函数式的高层次抽象都会得到改进,但函数式编程概念显著增加了可以用这些抽象来覆盖的代码量。
这看起来有点简单,但很多程序员倾向于手动编写低层次的关键性能代码,有时甚至用汇编语言。这种做法有一定的好处,但这种优化只针对特定的平台,而且阻碍了编译器对其他平台代码的优化。
再来看一下 sum 函数。针对预取指令的系统进行优化,可以在内部循环中一次取两个(或更多)条目,而不是一次只取一个。这可以减少代码中的跳转次数,因此 CPU 一般会预取到正确的指令,而且在目标系统中可大幅提高性能。但如果在另一不同的平台上运行这个程序会怎样呢?对于某些平台来说,其原始的循环可能已经是优化了的;对于其他平台,有可能每次循环能对更多的条目进行累加。有些系统甚至可以提供CPU级的指来实现这个函数的功能。
通过这种方式手动优化代码,针对的只有一个平台,而失去了其他所有平台的优化。如果使用高层次抽象,就可以依赖其他的人对代码进行优化。绝大多数STL实现都对目标平台和编译器进行了特定的优化。
⭐️内容取自译者程继洪、孙玉梅、娄山佑《函数式编程》,仅从中取出个人以为需要纪录的内容。不追求内容的完整性,却也不会丢失所记内容的逻辑性。如果需要了解细致,建议读原书。
