fdbbee5af42e12decf3fb156f232fd28.png
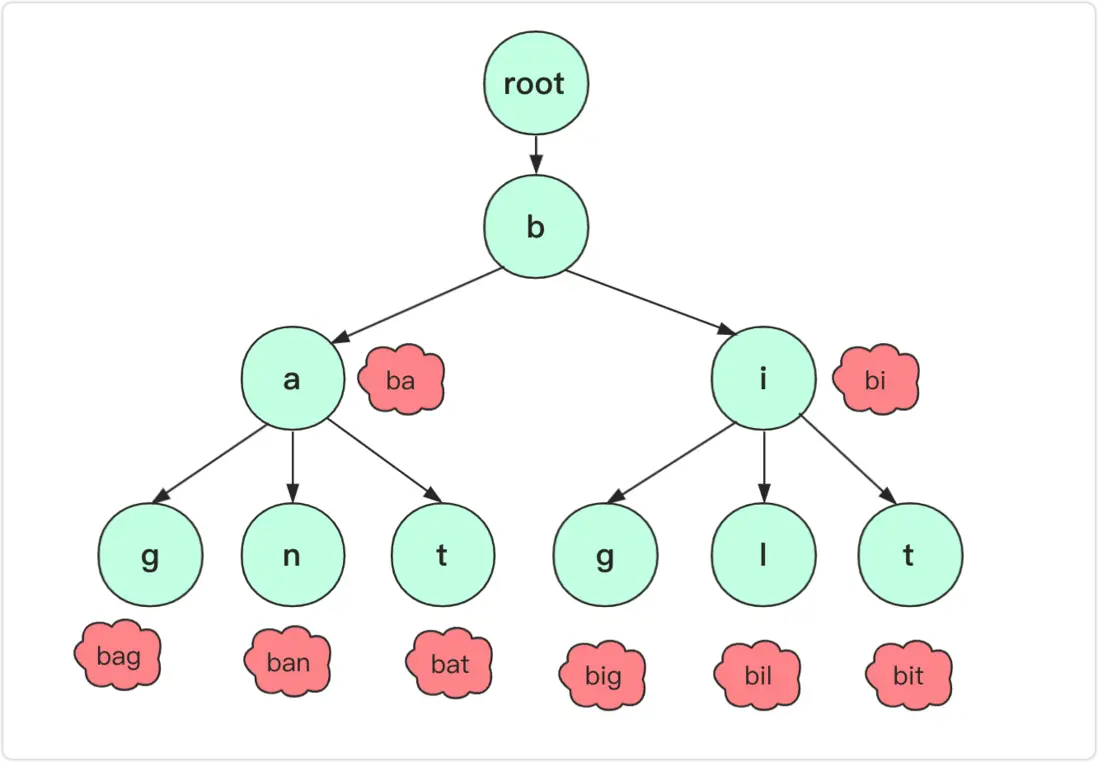
性质:
它是一棵多叉树,每个节点代表一个字符。根节点不包含字符 ,除根节点外的每个节点都包含一个字符
从根节点到某一节点的路径上经过的字符连接起来,即为该节点对应的字符串
每个节点可能有多个子节点,每个子节点对应一个不同的字符
通常在表示字符串集合的字典树中,会有一些特殊标记来表示某个节点是否是一个字符串的结尾
1 2 3 4 5 6 7 struct Node {explicit Node (char ch, size_t freq = 0 ) : ch_(ch), freq_(freq) {char ch_;size_t freq_;char , Node *> children_;
完整代码:字典树
插入 1 2 3 4 5 6 7 8 9 10 11 12 13 void insert (const string &word) if (word.empty ()) return ;auto curNode = root_;for (const auto &ch : word) {auto it = curNode->children_.find (ch);if (it == curNode->children_.end ()) { new Node (ch);
遍历字符串的每个字符,如果当前节点中没有该字符就新增。
当遍历完成,curNode 就是记录字符串的末尾字符,频率加
1,代表当前字符添加成功。
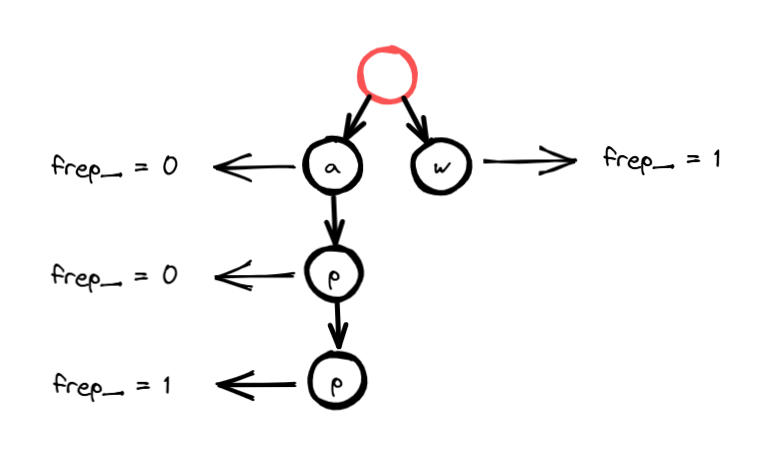
特别注意,除了记录添加字符串的末尾字符的节点频率加
1,其余频率为默认值 0:
image20250318175119267.png
查找 1 2 3 4 5 6 7 8 9 10 11 12 int search (const string &word) if (word.empty ()) return 0 ;auto curNode = root_;for (const auto &ch : word) {auto it = curNode->children_.find (ch);if (it == root_->children_.end ()) {return 0 ;return curNode->freq_;
如果 频率 为 0,代表不存在该字符串的记录。
删除 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void remove (const string &word) if (word.empty ()) return ;if (search (word) == 0 ) return ; remove (root_, word, 0 );Node *remove (Node *curNode, const string &word, size_t depth) {if (curNode == nullptr ) return nullptr ;if (depth == word.size ()) {if (curNode->freq_ > 0 ) {0 ; if (curNode->children_.empty ()) { delete curNode;nullptr ;return curNode;auto it = curNode->children_.find (word[depth]);auto node = remove (it->second, word, depth + 1 );if (node == nullptr ) {erase (it); if (curNode->children_.empty () && curNode->freq_ < 1 ) { delete curNode;nullptr ;return curNode;
通过前面的 search 方法确保有字符串的记录,才去考虑删除。
depth
既可以获取当前要查询的字符,还可以知道什么时候不再往下继续查询,到删除的必要了。
如果 当前节点 的 freq_ > 0,置为 0 就代表删除该字符。
可是这远远不够,还需要删除这些字符连接起来的节点,但是也不能一股气全部删除,还是要考虑删除的情景:
当要删除的单词是其它单词的前缀时,只需将该节点的 freq 设置为 0
即可,不需要删除该节点及其子节点。例如,字典树中有 apple 和
app,若要删除 app,则只需将 app 对应的节点的 freq 设为 0,apple
仍然保留。
若要删除的单词和其它单词有公共前缀,该路径上的公共前缀需要保留,删除公共前缀之后的部分即可。例如,字典树中有
app 和 apple,若要删除 apple,app 仍然会保留。
如果删除的单词后面没有后缀,可以递归从后往前删除,直到遇到当前节点依旧是其他节点的前缀位置。
前缀匹配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 vector<string> prefix (const string &word) { if (word.empty ()) return res;auto curNode = root_;for (const auto ch : word) {auto it = curNode->children_.find (ch);if (it == root_->children_.end ()) { return res;if (curNode->freq_ > 0 ) { push_back (word);nodeBack (curNode, const_cast <string &>(word), res);return res;void nodeBack (Node *curNode, string &word, vector<string> &wordVec) if (curNode == nullptr ) return ;for (auto &child : curNode->children_) {push_back (child.first);nodeBack (child.second, word, wordVec);if (child.second->freq_ > 0 ) {push_back (word);pop_back ();
先把用户输入的前缀匹配一下,这是最根本的。
用户输入的前缀也可以视为一个单词,如果 freq_ 大于 0,添加到
容器中。
接下来 nodeBack 函数开始递归收集
前缀后面的所有字符串并添加到容器中,这里用到回溯的思想。
输出全部字符串 1 2 3 4 5 6 7 8 9 void preOrder () auto root = root_;nodeBack (root, word, res);for (const auto &str : res) {
理解前面的 nodeBack
也就不难,字典树的根节点是不包含任何字符的,作为第一个参数,就可以把所有字符串都收集起来了。