相似度算法之Simhash
Simhash 是一种用于高效计算文本相似度的算法,主要用于检测重复内容(如网页去重、文档去重等)。它的核心思想是通过哈希技术将文本映射到一个固定长度的二进制指纹(通常是 64 位或 128 位),然后使用汉明距离来衡量两个文本的相似性。
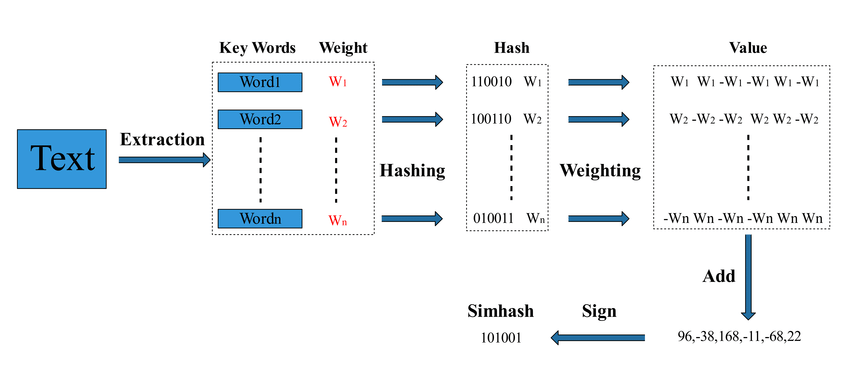
步骤:
- 分词:将文本拆分成若干特征(如单词),然后去除停用词。
- 特征哈希:对每个特征计算哈希值(如 64 位整数)。
- 加权累加:每个哈希值按位拆分,权重通过 TF/IDF
算法计算出来
- 如果某一位是
1,则对应的权重加到该位; - 如果是
0,则对应的权重减去该位。
- 如果某一位是
- 构造
Simhash(降维):如果某个位的权重大于零,则该位设为
1,否则设为0。
(人工智能,1)、(大数据,2)、(科技,3)、(互联网,4)、(机器学习,5)
上面是我们分词并去除停用词之后得到的特征词,并且计算出这些特征词的权重(特征词的右侧数字)。
接下来需要对这些关键词进行编码,首先对5个词进行普通的hash之后得到一个N位(一般为32位或是64位)的二进制,为了方便书写,这里假设N为5,则:
人工智能: 00101
大数据: 11001
科技: 00110
互联网: 10101
机器学习: 01011
针对每一个hash后的词,相应位置是1的,权重W取正,相应位置是0的,权重W取负,及变为:
人工智能: 00101 ---> [-1,-1,1,-1,1]
大数据: 11001 ---> [2,2,-2,-2,2]
科技: 00110 ---> [-3,-3,3,3,-3]
互联网: 10101 ---> [4,-4,4,-4,4]
机器学习: 01011 ---> [-5,5,-5,5,5]
对上述变换后的列表进行列向累加得到:[-3, -1, 1, 1, 9]。
再对上述累加后的结果进行变换,对应位置为正数时取1,对应位置为负数时取0。
即:[-3, -1, 1, 1, 9] ---> 00111
汉明距离
汉明距离是用于衡量两个等长二进制串(或字符串)之间不同位的个数。它常用于 错误检测、纠错编码 以及 相似度计算(如 Simhash)。
1 | |
逐位比较:
1 | |
海明距离为 3。
TF/IDF 算法
TF-IDF 是一种用于文本挖掘和信息检索的加权统计方法,广泛应用于 搜索引擎、关键字提取、文本相似度计算 等领域。
它用于衡量某个 词(Term) 在 文档集合(Corpus) 中的重要性。
TF-IDF有两层意思,一层是"词频"(Term Frequency,缩写为TF),另一层是"逆文档频率"(Inverse Document Frequency,缩写为IDF)。
当有TF(词频)和IDF(逆文档频率)后,将这两个词相乘,就能得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么一般而言这个词在这篇文章的重要性会越高,所以通过计算文章中各个词的TF-IDF,由大到小排序,排在最前面的几个词,就是该文章的关键词。
(1)词频(Term Frequency,TF)
TF 衡量某个词 t 在某个文档 d 中出现的频率: \[ TF(t, d) = \frac{\text{词 } t \text{ 在文档 } d \text{ 中出现的次数}}{\text{文档 } d \text{ 的总词数}} \]
- 高 TF:某个词在文档中出现频率高,可能是该文档的重要内容。
- 低 TF:某个词出现频率低,可能是次要内容。
(2)逆文档频率(Inverse Document Frequency,IDF)
IDF 衡量某个词 t 在整个文档集合(所有文档) D 中的重要性:
\[ IDF(t, D) = \log \left( \frac{N}{\text{包含词 } t \text{ 的文档数} + 1} \right) \]
其中:
- N 是总文档数;
- 1 避免分母为 0(平滑处理)。
(3)TF-IDF 计算
\[ TFIDF(t, d, D) = TF(t, d) \times IDF(t, D) \]
- 高 TF-IDF:词在某个文档中频率高,且在其他文档中较少出现,说明这个词对该文档很重要。
- 低 TF-IDF:词在大多数文档中都出现,可能是常见词,没有区分度。
实例
1 | |
让我们关注cat(忽略大小写) 这个词,看看 TF-IDF 如何评估它的重要性。
计算 TF:
1 | |
计算 IDF:
语料库中的文档总数为 3,包含术语 “cat” 的文档数:2 (文档 1 和文档 3)。
所以 IDF ≈ 0.176
计算 cat 的 TF/IDF:

TF-IDF 分数越高,意味着该术语在该特定文档中更重要。
参考文章
https://zhuanlan.zhihu.com/p/81026564
https://www.geeksforgeeks.org/understanding-tf-idf-term-frequency-inverse-document-frequency/

