跳表是一种概率型数据结构,其平均操作复杂度为
O(log n)。它通过多层链表实现快速查找、插入和删除操作。
节点定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| struct Node {
int key_;
int value_;
int level_;
Node **forward_;
Node(int key, int value, int level) : key_(key), value_(value), level_(level) {
forward_ = new Node *[level + 1];
for (int i = 0; i < level; ++i) {
forward_[i] = nullptr;
}
}
~Node() {
delete[] forward_;
}
};
|
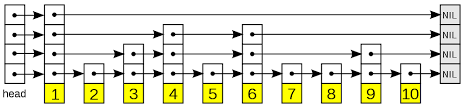
示意图:
 cc4842bc5b93c1713cccca8a80110c8b.png
cc4842bc5b93c1713cccca8a80110c8b.png
每个 Node 记录 key-value,还记录自己的 level(如果 level 是
4,就代表有 4 层都有该节点的记录,即 forward_ 数组的大小,如图中的元素
1)。
在一个就是最关键的
forward_,存储该节点在不同层次上的后继节点的指针。在链表操作中我们是通过
next 指针获取下一个节点,但是在跳表中不是。
跳表中 forward_[i] 记录着第 i
层的下一个节点(右侧方向)。至于下一层,由于是数组,有序访问即可(当前下标
+ 1)。
完整的代码:跳表
查找
查找元素 16:
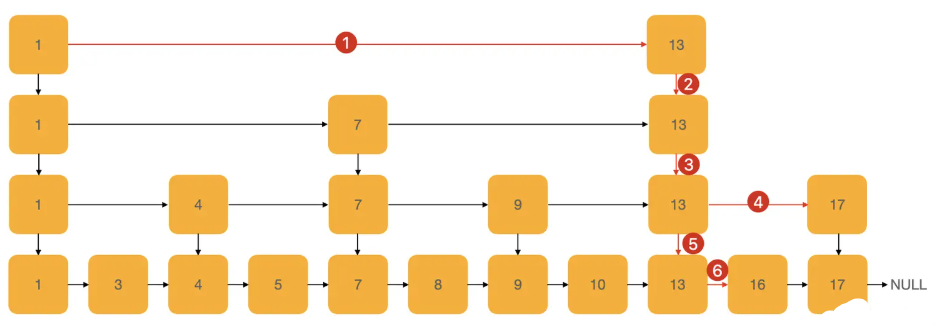 image20250321105338828.png
image20250321105338828.png
逐层向下逼近目标值:
- 从 最高层(跨度最大)开始搜索,先快速跳跃到
key 可能存在的区间
- 一旦某个
forward_[cur_level] 指向的值 大于等于
key,说明已经越过了目标值,我们就下降到下一层继续搜索
最低层(level 0)存储所有元素:
- 在所有层级搜索完之后,
cur_node 停留在 最接近
key 但小于 key 的位置
- 这时,
cur_node->forward_[0] 可能正好是目标
key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| Node *search(int key) {
Node *cur_node = head_;
for (int cur_level = level_; cur_level >= 0; --cur_level) {
while (cur_node->forward_[cur_level] != nullptr
&& cur_node->forward_[cur_level]->key_ < key) {
cur_node = cur_node->forward_[cur_level];
}
}
cur_node = cur_node->forward_[0];
if (cur_node != nullptr && cur_node->key_ == key) {
return cur_node;
}
return nullptr;
}
|
添加
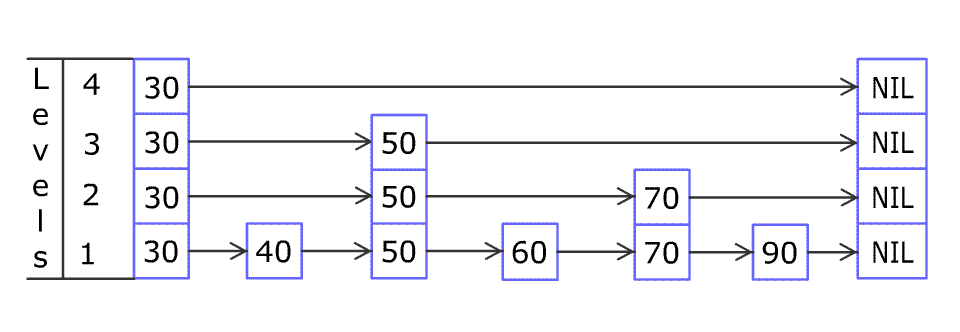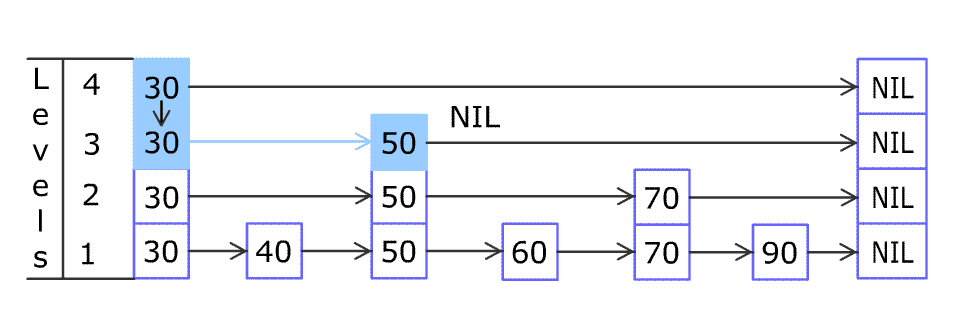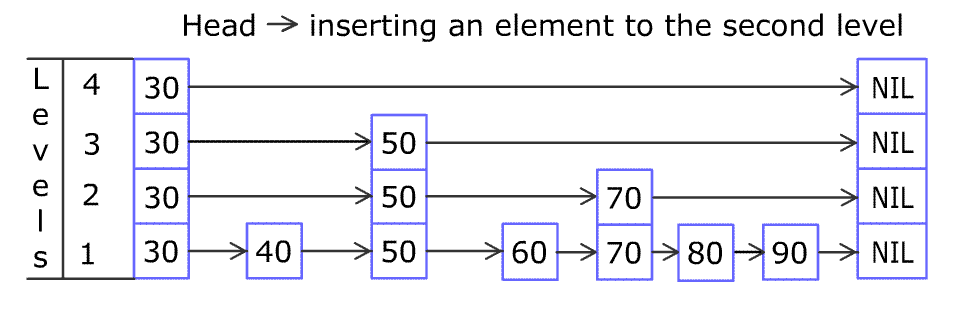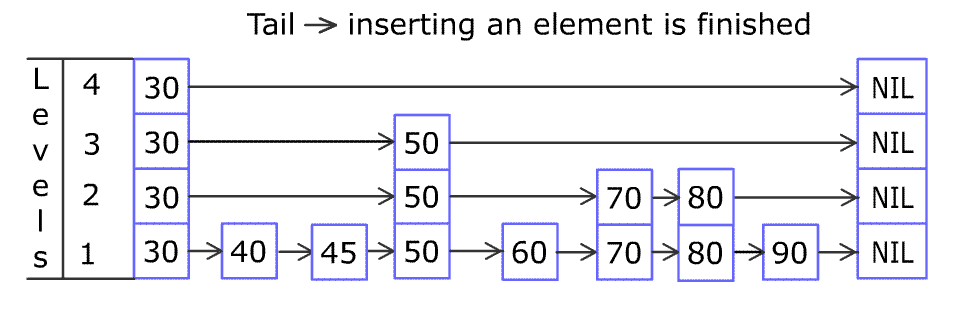
添加元素 80:
 skiplist01.gif
skiplist01.gif
forward_ 记录后驱节点,而代码中的局部 update
记录前驱节点,因为方便插入。
从最高层开始寻找,离开 while 循环,update 就会记录下 cur_node。
跳表中添加一个新节点,会随机得到一个
层数。如果大于当前跳表记录的当前层数,就得 更新
update,继续记录多出点层的前驱节点为 head_。
就可以开始在各层中插入了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| void insert(int key, int value) {
Node *update[MAX_LEVEL + 1];
Node *cur_node = head_;
for (int cur_level = level_; cur_level >= 0; --cur_level) {
while (cur_node->forward_[cur_level] != nullptr
&& cur_node->forward_[cur_level]->key_ < key) {
cur_node = cur_node->forward_[cur_level];
}
update[cur_level] = cur_node;
}
cur_node = cur_node->forward_[0];
if (cur_node != nullptr && cur_node->key_ == key) {
cur_node->value_ = value;
return;
}
int new_level = randomLevel();
if (new_level > level_) {
for (int i = level_ + 1; i <= new_level; ++i) {
update[i] = head_;
}
level_ = new_level;
}
Node *new_node = new Node(key, value, new_level);
for (int i = 0; i <= new_level; ++i) {
new_node->forward_[i] = update[i]->forward_[i];
update[i]->forward_[i] = new_node;
}
}
|
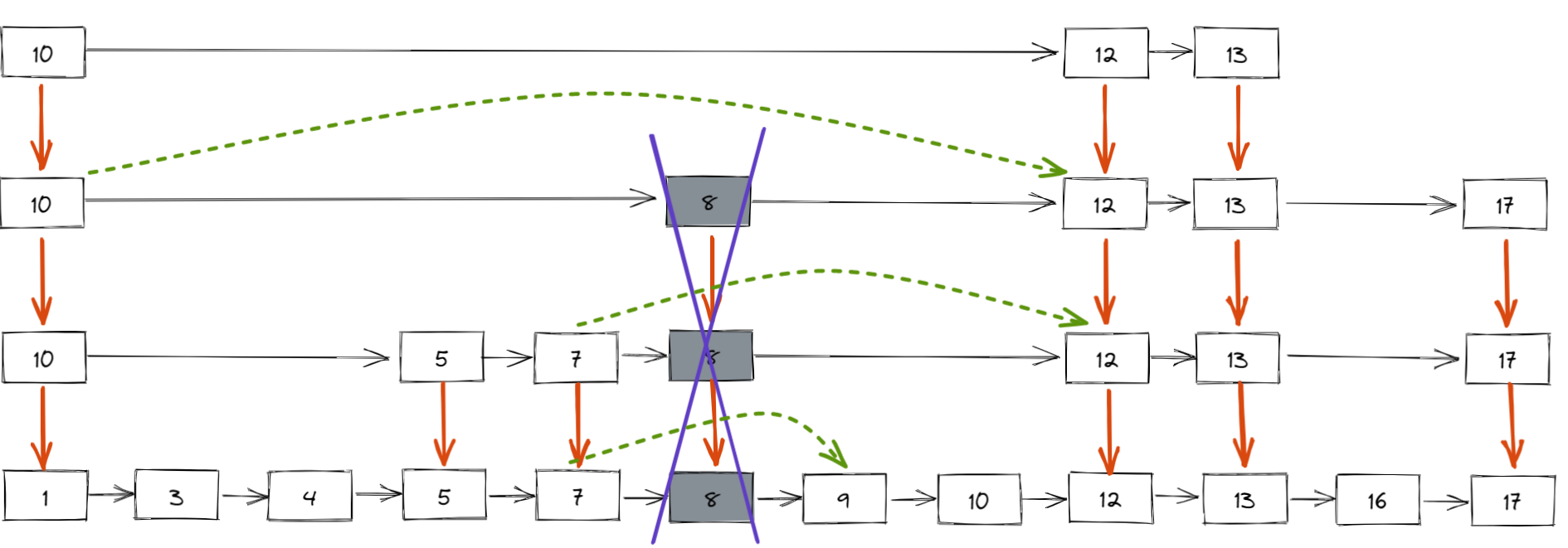
删除
 a632409bfc6c1d2e6c9269ba04434935.png
a632409bfc6c1d2e6c9269ba04434935.png
同样,需要记录删除节点的前驱节点,通过 update 数组。
如果元素确实存在,就可以考虑删除。可能存在删除节点后,跳表层数减少的情况,记得调整跳表的
level。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| void remove(int key) {
Node *update[MAX_LEVEL + 1];
Node *cur_node = head_;
for (int cur_level = level_; cur_level >= 0; --cur_level) {
while (cur_node->forward_[cur_level] != nullptr
&& cur_node->forward_[cur_level]->key_ < key) {
cur_node = cur_node->forward_[cur_level];
}
update[cur_level] = cur_node;
}
cur_node = cur_node->forward_[0];
if (cur_node != nullptr && cur_node->key_ == key) {
for (int i = 0; i <= level_; ++i) {
if (update[i]->forward_[i] != cur_node) break;
update[i]->forward_[i] = cur_node->forward_[i];
}
delete cur_node;
while (level_ > 0 && head_->forward_[level_] == nullptr) {
level_--;
}
}
}
|

